对于网页文档进行更细粒度的分析可以有效改进检索的精度。一般来说一个文档都是有一个主题的,同时一篇文档中可能包含多个sub-topic,比如一篇关于分析日元汇率上升的文档中,可能包含近期日元的走势及分析,进一步可能包含英国脱欧的分析,对日本旅游业的影响,制造业的影响,与其他货币的比较等内容。尽管这篇文档整体主题是关于经济的,然是具体其中也包含了各个子话题。如果可以识别划分关于不同子话题的段落,可以有效的改进检索。同样的,多个文档可能包含这些子话题的段落,如果能将这些文档的段落中具有相同子话题的文档关联起来,可以进一步挖掘文档间的关系用于改进检索,因为有些用户只是关注文档中某一特定子话题的内容。
这个任务就是identifying similar segments from multiple similar documents,一个直观的展示是:
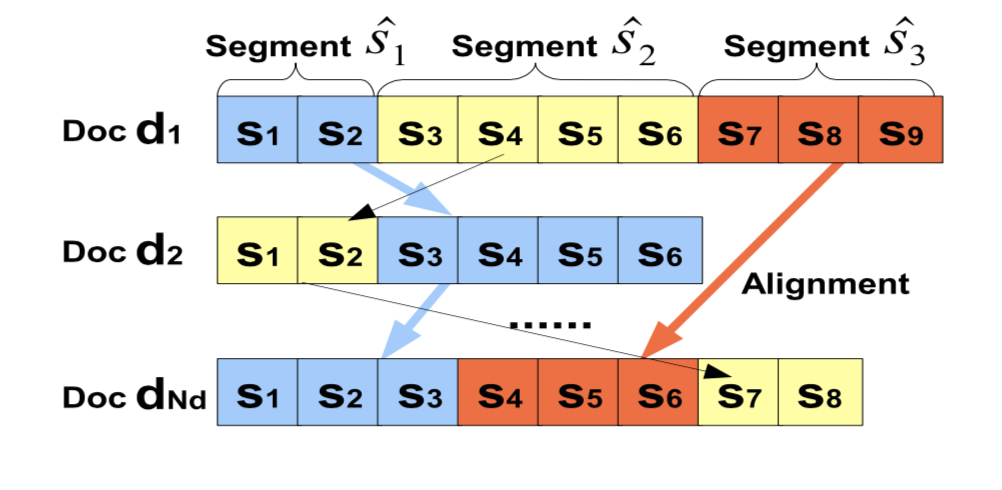
论文Topic Segmentation with Shared Topic Detection and Alignment of Multiple Documents给出了一个基于Mutual information(MI)的解决方法,以及带有term weights的Weighted mutual information(WMI)的解决方案。
问题可以定义为:
terms集合 $T=\lbrace t_1, t_2, …, t_l\rbrace $
documents集合 $D=\lbrace d_1, d_2, …, d_n\rbrace $
文档 $d$ 的sentences $S_d=\lbrace s_1, s_2, …, s_m\rbrace$,其中$m$表示文档 $d$的sentences的个数。
Segments集合(准确的说是topic集合,这里的每个segment不是各个文档的片段,而是一个全局topic)$\widehat{S}=\lbrace \widehat{s_1}, \widehat{s_2}, …, \widehat{s_p}\rbrace $ ,也就是每个文档的$\widehat{s_1}$的topic都是相同的,尽管有些documents的$\widehat{s_1}$是空的,也就是不存在对应的sentence。也就是正如前面所说的,论文中这里指的segment其实就是topic(比较迷惑),而topic数目是要预定义的(尽管这个数字一般是没法确定,取一个大的数字是比较合适的,但是增加计算复杂度。)
所要解决的问题就是对每个文档进行segmentation以及找出多个文档中各个segment的alignment:
$$\begin{aligned}
Seg_d : \lbrace s_1, s_2, ..., s_{n_d}\rbrace \to \lbrace \widehat{s_{d1}}, \widehat{s_{d2}}, ..., \widehat{s_{?}}\rbrace
\end{aligned}$$
(这里原文的表述和公式相当让人迷惑,所以做了调整)
其基本假设本质上还是把sentence作为bag of words处理,并假设term和各个topic关联程度不同。比如toyota会和汽车topic关联比较紧密(也就是在关于汽车topic的段落中toyota出现可能性会比关于文学topic的段落中大,也就是topic-model的基本假设),以此定义了mutual inforamtion(MI),其实就是clustering中MI的定义。
$$\begin{aligned}
I(X;Y) = \sum_{x\in X}\sum_{y\in Y}p(x, y)log\frac{p(x,y)}{p(x)p(y)}
\end{aligned}$$
对多个文档进行segmentation以及alignment的问题也就变成了如何划分每个文档以及alignment,使得最终的MI取得最大值,也就是MI就是这个问题的目标函数。具体在这问题中,MI也就是:
$$\begin{aligned}
I(\widehat{T};\widehat{S}) = \sum_{\widehat{t}\in \widehat{T}}\sum_{\widehat{s}\in \widehat{S}}p(\widehat{t}, \widehat{s})log\frac{p(\widehat{t},\widehat{s})}{p(\widehat{t})p(\widehat{s})}
\end{aligned}$$
需要注意的是$\widehat{T}$可以直接是原来定义的$T$,也可以是term的cluster集合,也就是term-clustering。term-clustering经常用于改进document cluster,也就是把相近的term放到一个cluster中,然后分析时基于这些term cluster,而不是原来单个单个的terms。这篇论文在计算最优的segmentation和alignment同时也可以考虑term-clustering,并且生成term clustering。此外论文还考虑到terms的类型不同而应该具有不同的权重,并很巧妙将其融入到MI中从而得到Weighted Mutual Information,并设计了巧妙的算法用于估计term的权重,以实现最终优化segmentation和alignment。关于term-clustering和weighted mutual information具体思想及算法可以参考原文。
为了求得最佳组合以得到best目标函数值,最直接的计算方法当然是对于每个文档,每个sentence,划分到各个segment中,取使得terms和segments(topics)的MI(或WMI)最大的组合作为最优segmentation和alignment。
然而如果列举每种组合,这个就是NP-hard问题了,在文档数量比较大时或者topic数量比较多时计算代价会非常高甚至不可计算。所以论文中进一步提出了一个Iterative greedy的算法用于计算local optimal segmentation and alignment(但不能保证是全局最佳)用于使得问题可计算,并在计算过程中使用dynamic programming等进行优化。具体算法如下,其中分为了各个阶段和步骤,可以根据是否是只有一个文档,是否需要进行term-clustering,是否需要进行term weight estimation进行不同步骤的选择。
